Оправданная предусмотрительность: как защитить дата-центр от катастрофы
Неприятности время от времени случаются. Сбои в работе, аварии или даже катастрофы — все это может произойти даже с самыми надежными дата-центрами. Но есть отрасли и сферы деятельности, для которых недопустимы даже малейшие простои в работе ЦОДа, и в этом случае необходимо катастрофоустойчивое решение. До недавнего времени подобные системы были дорогостоящими, однако ситуация быстро меняется в лучшую сторону благодаря сервисному подходу.
Об этом и многом другом в интервью с нашими экспертами: Сергеем Немченковым, генеральным директором АО «Атомдата-Центр» (компания-интегратор инфраструктуры геораспределенной сети ЦОД Концерна «Росэнергоатом») и с Салаватом Рахматуллиным, генеральным директором АО «Атомдата-Иннополис» (компания занимается проектом строительства ЦОД «Иннополис» в Республике Татарстан, который будет введен в эксплуатацию до конца 2023 года).

Ценность данных в современном мире продолжает расти — день ото дня появляется все больше организаций, для которых информация является, по сути, важнейшим элементом деятельности, а для ее сбора, обработки и надежного хранения разворачиваются целые комплексные инфраструктуры в виде дата-центров. Конечно, каждая компания стремится обезопасить свой ЦОД от любых негативных событий — сбоев в работе и аварий. Все ключевые инженерные подсистемы дублируются, обеспечивается кластеризация серверов, резервное копирование данных и т. д., и в большинстве случаев этих мер достаточно. Однако совсем немногие задаются вопросом, что произойдет со всем оборудованием и носителями информации, если ЦОД будет уничтожен полностью?
Пожар, наводнение, землетрясение, техногенная катастрофа или теракт — вероятность всех этих ужасных событий для некоторых дата-центров практически не отличается от нулевой. Куда более реальную опасность представляют аварии, связанные с ИТ-оборудованием или каналами связи, когда ЦОД в целом работает, но доступ к данным, которые в нем хранились, временно невозможен. Конечно, можно принять все эти риски как допустимые и спокойно жить дальше. Или же, понимая, что даже небольшой перебой в работе может обойтись неоправданно дорого, построить катастрофоустойчивое решение.
Когда потеря данных — потеря бизнеса. Как обезопасить свой ЦОД.
«В Республике Татарстан немало компаний и государственных организаций, для которых перерыв в работе дата-центра даже на несколько минут — это ЧП и ощутимые финансовые потери. Скажем, для крупных сервисов бронирования авиабилетов/гостиниц, биржевых площадок, международных банков стоимость каждой минуты простоя может вылиться в миллионные убытки», - рассказал Салават Рахматуллин.
Авария, которая привела к недоступности сервисов или данных на несколько часов, почти гарантированно оказывает серьезное негативное влияние на бизнес большинства крупных компаний и ведет к значительным материальным и репутационным потерям. Разумеется, ценность различных данных может существенно отличаться. Есть информация, потерю которой никто не заметит, но у любой организации имеются и критичные данные, утрата которых чревата серьезными последствиями, вплоть до краха бизнеса. Скажем, длительная недоступность сервера с финансовыми данными компании во время формирования квартального или годового отчета может стать не только причиной стресса для сотрудников бухгалтерии и руководства, но и привести к ощутимым штрафам за несвоевременную подачу налоговой документации.
Иногда в случае особенно тяжелых аварий или катастроф перебой в работе может исчисляться днями — это почти гарантированно означает коллапс для бизнеса. Столь серьезные сбои, конечно, случаются крайне редко, но именно потому, что большинство организаций заранее просчитывают риски и принимают соответствующие решения, направленные на обеспечение устойчивости ИТ-инфраструктуры к любым негативным воздействиям.

Салават Рахматуллин, генеральный директор АО "Атомдата-Иннополис"
По мнению Салавата, надо соблюдать баланс: затраты на обеспечение надежности и катастрофоустойчивости должны соответствовать ценности данных и сервисов, развернутых в дата-центре. На первый взгляд, самое простое решение — построить два собственных ЦОДа на определенном удалении друг от друга с дублирующимися функциями. При аварии одного из них второй обеспечил бы нормальную работу ИТ-инфраструктуры и сохранность данных. Но такой подход не всегда оправдан с экономической точки зрения, считает Салават Рахматуллин. Благо сейчас два и более собственных ЦОДа не единственный вариант обеспечения катастрофоустойчивости — есть, например, варианты с арендой коммерческих площадок и применением облачных технологий.
«Так что гарантированная катастрофоустойчивость в наши дни доступна более широкому кругу компаний, чем это было несколько лет назад, — теперь это уже не экзотика, а довольно распространенное явление и даже необходимое», - отметил Салават.
Так, в России решения такого рода активно используют финансовые организации, торговые сети, производственные и сервисные компании. Банки, например, к этому подталкивают законодательные требования по обеспечению непрерывности бизнеса. Для других же организаций данных подход, как правило, результат оценки потенциальных рисков для бизнеса: в условиях высококонкурентных рынков любые сбои в работе — это, как правило, не только сиюминутные финансовые потери, но и более долгосрочные убытки, связанные с потерей клиентской базы. Соответственно, необходимо исключить даже малейшую возможность недоступности данных и сервисов.
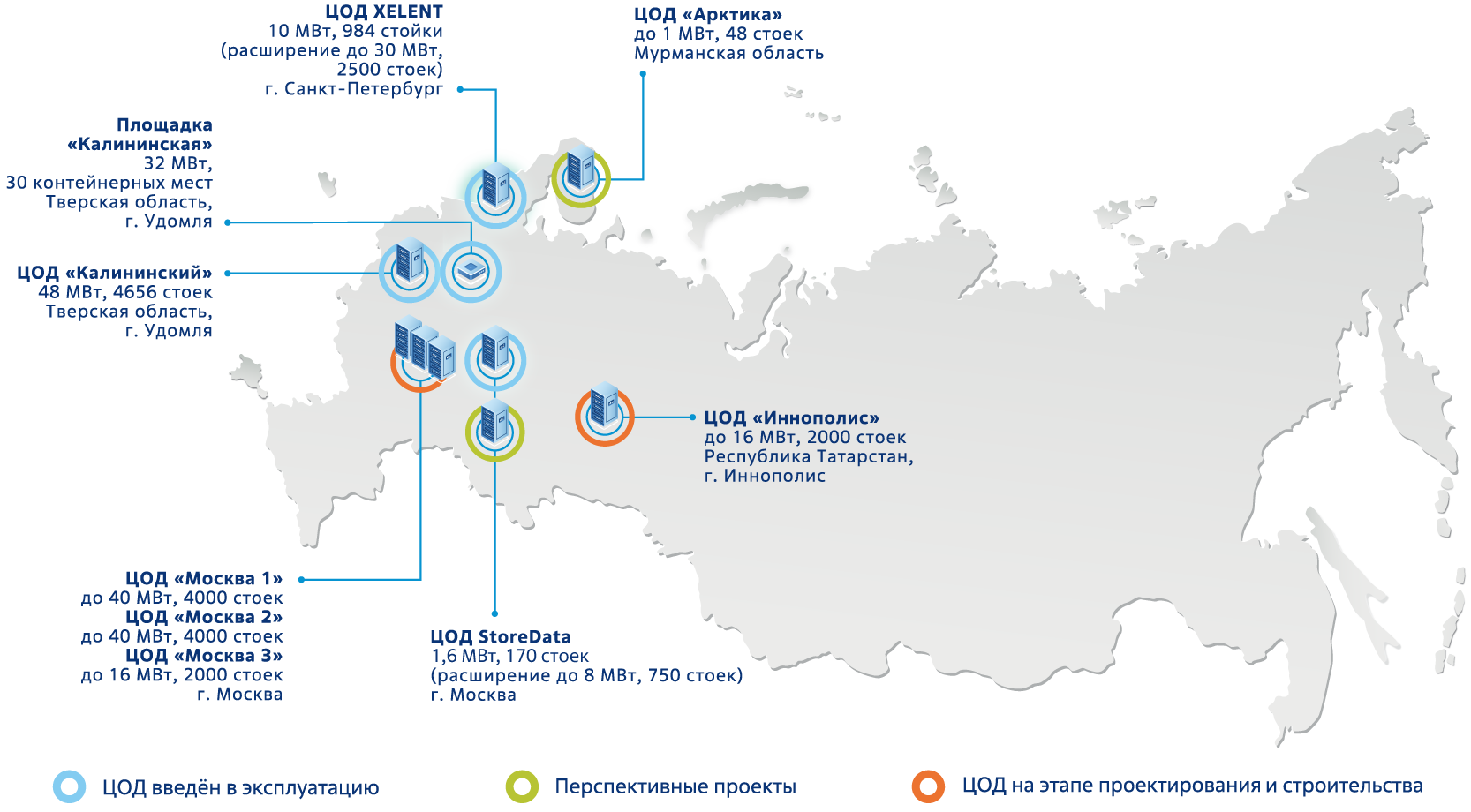
«Концепция создания геораспределенной сети подразумевает не один ЦОД в чистом поле, а создание нескольких дата-центров, географически разнесенных по территории, в частности Российской Федерации, и объединенных между собой надежной канальной составляющей. Когда есть ЦОДы и каналы, тогда появляется прекрасная возможность по надежному функционированию ИТ-инфраструктуры и резервирования, с точки зрения хранения информации в различных ЦОДах», - включается в диалог Сергей Немченков.
«Фактически, чтобы не произошло с каким-то одним центром обработки данных, какие-то чисто теоретические остановки или возможные перебои в работе оборудования — сервис продолжит предоставляться клиенту из другого дата-центра. На текущий момент у нас три таких дата-центра — в городах Удомля, Санкт-Петербург и Москва», - отмечает Сергей.
Немного о терминологи
В контексте обеспечения защиты данных (и в более широком смысле — ИТ-инфраструктуры компаний) от всевозможных сбоев и аварий часто фигурирует несколько популярных терминов: «катастрофоустойчивость», «отказоустойчивость», «высокая доступность», «непрерывность бизнеса». Их нередко употребляют в качестве синонимов, но фактически они обозначают различные явления.
Так, катастрофоустойчивость (Disaster Recovery, DR) говорит о способности системы (здесь и далее мы будем говорить о дата-центрах) к восстановлению после серьезных аварий, включая природные катаклизмы, происшествия техногенного характера, теракты. Главное отличие катастрофоустойчивого решения от всех остальных — отсутствие единых источников простоя. То есть даже полное уничтожение любой подсистемы или ЦОДа целиком не приведет к полной остановке работы ИТ-инфраструктуры и/или потере данных компании.
В свою очередь отказоустойчивость (Fault-Tolerance, FT) в основном относится к локальной площадке и обозначает свойство дата-центра сохранять работоспособность после отказа одного или нескольких компонентов.
Высокая доступность (High Availability, HA) означает, что решение гарантирует пользователям возможность непрерывного использования дата-центра в течение определенного промежутка времени. Высокая доступность, как правило, выражается с помощью коэффициента, состоящего из некоторого количества девяток.
Например, для Tier III доступность составляет 99,98%, а точнее это коэффициент отказоустойчивости, время простоя максимально - 1,6 часа в год.
Tier IV – 999,995%, время простоя - 26 минут в год. Указанная величина - это то к чему все стремятся.
Сегодня в контексте дата-центров «отказоустойчивость» и «высокая доступность», несмотря на то, что разница между этими терминами есть, по ряду причин часто используются как синонимы.
Важной характеристикой является также непрерывность бизнеса (Business Continuity, ВС). Она говорит о способности системы выполнять бизнес-критичные задачи без перебоев. Обеспечение непрерывности бизнеса лежит не только в технической плоскости, но и охватывает широкий пласт организационных процессов внутри компании.
Надежность или скорость? Поиск баланса по мнению наших экспертов
Катастрофоустойчивость — это наивысшая стадия надежности для дата-центра, но для ее обеспечения должен соблюдаться ряд требований. Во-первых, естественно, нужен резервный ЦОД, по характеристикам не уступающий основной площадке, но размещенный на значительном удалении от нее. «Значительное удаление» — это десятки, а лучше сотни километров, чтобы ЦОДы не находились в одном регионе. По распространенной сегодня мировой практике, минимальное расстояние — 100 км, а оптимальное — 200-400 км.
Конечно, в теории можно было бы размещать дата-центры еще дальше, но тогда можно столкнуться с другой проблемой — обеспечением скорости работы. Дело в том, что распределение ресурсов по нескольким площадкам требует продублированных каналов связи, механизмов репликации данных между СХД, внедрения механизмов резервного копирования и восстановления ИТ-систем, включая инфраструктуры виртуальных машин. Кроме того, необходим механизм синхронизации данных для обеспечения их актуальности в случае недоступности одной из площадок и т. д.

ЦОД Xelent
Критическим параметром, помимо пропускной способности каналов связи, является задержка в процессе передачи данных. При этом скорость распространения сигнала в кабеле имеет физические ограничения — даже в случае с волоконной оптикой это не более 200 тыс. км/с. На практике это обозначает, что задержка в передаче данных с основной площадки на резервную составляет примерно 0,5 миллисекунду (мс) на каждые 100 км ВОЛС. Для сравнения: скорость доступа к магнитным дискам корпоративного класса в серверах и СХД составляет не более 2-4 мс (для SSD-накопителей эта величина в десятки и сотни раз меньше).
В этих пределах оптимально сохранить и скорость обмена данными между основным и резервным ЦОДами, что и дает упомянутые 200-400 км. Но на практике задержки могут быть больше по целому ряду технически причин, поэтому различные технологии допускают и большие величины отставания.
Но есть и программное обеспечение баз данных (СУБД), которое очень плохо переносит задержки длительностью даже в десятки микросекунд (мкс). Это характерно, например, для банковских сервисов и любых других решений, связанных с огромным количеством транзакций. В таком случае резервная площадка должна быть как можно поближе: на расстоянии не более 40-50 км, в случае синхронной репликации данных между ЦОДами.
В общем случае возможны два основных сценария построения катастрофоустойчивых дата-центров: «активный — активный» и «активный — пассивный». В первом случае рабочие приложения и сервисы равномерно распределены между двумя и более площадками, и клиенты работают с теми ресурсами, которые в данный момент находятся ближе всего. Если один из дата-центров вдруг окажется недоступным, всю нагрузку моментально подхватит второй, резервный. Из возможных негативных последствий — некоторое снижение производительности. Единственная проблема в том, что, как правило, схема «активный — активный» подразумевает размещение площадок на небольшом удалении друг от друга.
В модели «активный — пассивный» расстояние между объектами не столь критично. Все пользователи работают только с одним дата-центром, а на втором поддерживается актуальная копия всех данных, образов и параметров основной ИТ-инфраструктуры. В случае аварии вся нагрузка автоматически (или, что бывает чаще, частично в ручном режиме) переводится на резервный ЦОД. На это может потребоваться некоторое время, величина которого рассчитывается исходя из критичности задач. Получаются как бы две взаимоисключающие задачи: для решения одной резервный ЦОД должен быть близко, а для другой — далеко. Что же делать? Строить уже три дата-центра — основной и два запасных? Как и в большинстве других сложных систем, надо найти баланс, благо возможностей для этого сегодня достаточно.
По мнению Сергея Немченкова, одним из наиболее востребованных вариантов сегодня является гибридная модель, когда компания, имея собственный ЦОД, разворачивает резервный дата-центр на арендованной площадке коммерческого оператора. Такой подход позволяет отказаться от капитальных вложений, а в ряде случаев дает возможность сэкономить и на операционных расходах, что немаловажно, ведь содержание собственного дата-центра — недешевое удовольствие. Кроме того, ставка на коммерческий ЦОД обеспечивает большую гибкость при построении катастрофоустойчивых решений — площадку можно выбирать исходя из текущих условий, которые могут со временем меняться. Влияет близость целевых рынков заказчика, региональный охват, различные технические параметры (например, доступность и качество каналов связи) и т. д. Построить собственный ЦОД — это раз и навсегда, арендная же модель допускает различные варианты.
В последние годы все большим спросом пользуются IaaS-сервисы для построения катастрофоустойчивых решений. На базе операторского облака можно как самостоятельно развернуть резервную площадку, так и воспользоваться специальной комплексной услугой, которая так и называется: аварийное восстановление как сервис (Disaster Recovery as a Service, DRaaS).

Сергей Немченков, Генеральный директор АО "Атомдата-Центр"
«Наша команда создает инфраструктуру для клиента под ключ. Мы организуем проектирование дата-центров, строительство, на всех площадках функционируют собственные службы эксплуатации. Мы формируем сервисную команду, которая обслуживает дата-центр, и предлагаем клиентам самый широкий спектр услуг — от размещения серверного телекоммуникационного оборудования, когда клиент привозит свое оборудование и размещает в нашем дата-центре, а наша сервисная служба занимается эксплуатацией, до более высокомаржинальной и клиентоориентированной истории», - отметил Сергей Немченков.
«Мы занимаемся, в том числе, облачной инфраструктурой. Покупаем и развиваем различные облачные платформы в рамках импортозамещения и фактически готовы предлагать заказчику инфраструктуру как сервис. За этим стоит модернизация ЦОДов, геораспределенная тематика, большое количество различных сервисов по копированию информации. Имея инфраструктуру, компетенции, команды и облака мы готовы, при наличии спроса, зайти в любой регион и создать там под ключ ЦОД-сервис и полную продуктовую линейку, как для государственного сектора, так и для коммерческих заказчиков», - добавил Салават Рахматуллин.
Disaster Recovery как стратегия
Строительство или аренда резервного дата-центра — это лишь часть необходимых действий. Для обеспечения катастрофоустойчивости нужны разработка и внедрение целого комплекса взаимосвязанных процедур, позволяющих восстановить работоспособность всей критически-важной ИТ-инфраструктуры на новой площадке после аварии или катастрофы. Здесь следует упомянуть два таких существенных параметра, как Recovery Point Objective (RPO) и Recovery Time Objective (RTO). Первый — это время, за которое данные могут быть потеряны без существенных последствий для деятельности компании. Скажем, критические обновления в ИТ-системе компании накапливаются каждые 10 минут — это и будет допустимый RPO (временное отставание состояния резервной копии от данных в основной системе). В свою очередь RTO определяет время, в течение которого работоспособность дата-центра или сервиса должна быть восстановлена в должном объеме. Показатели RPO зависят от подхода к организации резервного копирования и репликации данных, а RTO — от наличия инструментов, процедур и общей стратегии восстановления после аварий.
По сути, Disaster Recovery — это набор взаимосвязанных технологий и регламентов, обеспечивающий минимальную длительность простоев в случае аварии. Если стратегия разработана правильно, время восстановления составляет не более нескольких минут или даже секунд. Современные облачные и гибридные технологии позволяют поддерживать несколько актуальных копий данных (и целых виртуальных инфраструктур) сразу на нескольких площадках, что не только повышает надежность, но и зачастую увеличивает скорость восстановления работоспособности систем и приложений.
На практике за видимой легкостью описания стоят сложнейшие технологии, освоить которые непрофильной компании будет довольно сложно. Поэтому сегодня некоторые крупные операторы предлагают, как сервисы комплексные DRaaS: в ряде случаев они позволяют восстановить работоспособность ИТ-инфраструктуры буквально нажатием одной кнопки или максимум с помощью нескольких несложных операций.
«Не стоит смешивать понятия катастрофоустойчивости (Disaster Recovery) с простым созданием резервных копий (backup). Главное отличие здесь в том, что DR — это концепция, обеспечивающая защиту не только данных, но и всей ИТ-инфраструктуры. В случае DRaaS возобновление работы после самой жуткой аварии занимает, как правило, считаные минуты, а восстановление данных из бекапа может потребовать многих часов или даже дней», - уточнил Сергей Немченков.
Важно подчеркнуть, что катастрофоустойчивость — это не столько технологии, сколько целостная стратегия, предполагающая также ряд комплексных организационных мер. Скажем, на резервной площадке, кроме восстановления ИТ-инфраструктуры и данных, надо иметь возможность для организации рабочих мест персонала. Ведь не исключено, что в случае катастрофы на основной площадке операторам просто негде будет работать. В резервном ЦОДе все и всегда должно быть готово: система мониторинга и управления, терминалы, даже мебель. Кстати, сегодня подобный сервис доступен в наших коммерческих дата-центрах ГК «Росатом».

ЦОД StoreData
Помимо этого, крайне важно составить детальный план аварийного восстановления ИТ-инфраструктуры для различных вариантов развития событий. Идеальный вариант — это всеобъемлющий документ, который содержит инструкции для всех сотрудников, задействованных в процессе возобновления работоспособности дата-центра. Должно быть четкое понимание того, какие действия и в каком порядке необходимо предпринять, кто за что отвечает, кого поставить в известность и т.д. Разумеется, этот план желательно протестировать и периодически проводить учения, чтобы отработать все процедуры восстановления и свести к минимуму влияние человеческого фактора.
Сегодня с помощью современных сервисов вполне реально свести все негативные последствия к допустимому минимуму.
- Просмотров: 2236